Nachdem mich einige gefragt haben, wie man denn Tweetnest überhaupt installiert und auch die Heldenstadt meiner Anleitung nicht ganz folgen konnte, schreibe ich hier mal eine ausführlichere Anleitung.
Ich muss zugeben, die vorherige Anleitung zum Import seines Twitter-Archiv-Downloads setzte einiges an Wissen voraus und Tools wie z.B. git sind nicht auf jedem Rechner vorhanden und auch einen Shell-Zugang zu seiner Webseite hat nicht jeder.
Daher nun eine Anleitung für Leute mit Webspace auf dem PHP und MySQL verfügbar sind und sonst nichts weiter benötigt wird.
 Besorgt euch als Erstes den aktuellen Stand von Tweetnest. Wenn ihr den Link zum Fork des Users tralafiti anklickt, seht ihr einen Button mit der Aufschrift „Zip“, dort wird die aktuelle Version auf euren Rechner herunter geladen.
Besorgt euch als Erstes den aktuellen Stand von Tweetnest. Wenn ihr den Link zum Fork des Users tralafiti anklickt, seht ihr einen Button mit der Aufschrift „Zip“, dort wird die aktuelle Version auf euren Rechner herunter geladen.
Entpackt das Archiv, ihr erhaltet einen Ordner „tweetnest-master“. Diesen einfach in „tweetnest“ umbenennen und auf euren Webspace hochladen.
Nun öffnet im Browser die Adresse eurer Webseite und fügt „/tweetnest“ am Ende hinzu. Es sollte sich nun die Installationsseite von Tweetnest öffnen. Hier müsst ihr das Formular mit euren Daten ausfüllen.
Das Feld „TWITTER SCREEN NAME:“ ist selbst erklärend, hier tragt ihr euren Twitternamen ein. Auch die Zeitzoneneinstellung ist keine Hexerei. Für Deutschland wählt ihr bei „YOUR TIME ZONE:“ einfach „Europe/Berlin“ in dem Feld aus.
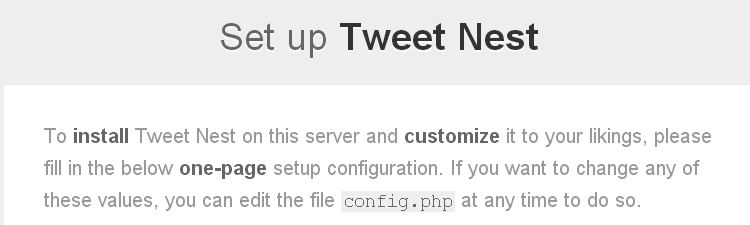
Die nächste Textbox ist mit „TWEET NEST PATH:“ benannt, diese wird automatisch gefüllt und sollte nur geändert werden, wenn ihr wirklich wisst, was ihr da macht. Also so stehen lassen.
Der nächste Abschnitt ist für die Datenbank-Konfiguration zuständig.
Tragt dort eure MySQL-Zugangsdaten ein, solltet ihr sie nicht wissen, schaut in der Doku eures Anbieters nach oder fragt diesen. Die Datenbank, die Tweetnest nutzen soll, muss schon vorhanden sein. Das Feld „TABLE NAME PREFIX:“ müsst ihr nicht ändern, im Normalfall ist die Einstellung in Ordnung.
Die nächsten zwei Felder drehen sich um das Admin-Passwort. Da ich ja davon ausgehe, dass ihr keinen Shell-Zugang zu eurem Webspace habt, setzt hier bitte ein Passwort. Dies sollte natürlich nicht identisch mit eurem Passwort bei Twitter sein.
 Die Haken bei „“FOLLOW ME” BUTTON“ und „SMARTYPANTS“ können einfach gesetzt bleiben.
Die Haken bei „“FOLLOW ME” BUTTON“ und „SMARTYPANTS“ können einfach gesetzt bleiben.
Das Feld „@ANYWHERE API KEY“ lasst ihr leer, dies ist für den Betrieb von Tweetnest nicht zwingen notwendig.
Ein Klick auf „Submit and Setup“ schließt die Einrichtung ab. Löscht im Anschluss die Datei „setup.php“ von eurem Webspace.

Der erste Schritt nach dem Setup ist das Aufrufen der Load User Seite. Diese erreicht ihr, indem ihr an die Domain eures Webspace „tweetnest/maintenance/loaduser.php“ anfügt.

Wenn ihr also „www.twitterarchiv.tld“ besitzt, so müsst ihr nun „www.twitterarchiv.tld/tweetnest/maintenance/loaduser.php“ aufrufen. Ihr werdet nach einem Benutzernamen und einem Passwort gefragt. Der Nutzername ist euer Twittername und das Passwort ist das bei der Installation vergebene Admin-Passwort.
Die nächsten Schritte kümmern sich um den Import des Twitter-Archivs. Die Zip-Datei, die ihr bei Twitter herunter laden könnt, enthält mehrere Dateien und Ordner. Uns interessieren nur die Dateien im Ordner „data\js\tweets“. Für jeden Monat gibt es dort eine Datei, der Dateiname ist immer wie folgt aufgebaut: „jjjj_mm.js“. So heißt beispielsweise die Datei für den Januar 2013 „2013_01.js“. Alle Javascript-Dateien aus dem tweets-Ordner nehmt ihr nun und ladet sie in den schon vorhandenen Ordner „tweetnest/archive“ auf eurem Webspace.
Nun wird die Seite „maintenance/loadarchive.php“ im Browser aufgerufen, die komplette URL müsst ihr euch wieder wie im oben beschriebenen Beispiel zusammenbauen.
Normalerweise startet man den Import über den Shell-Zugang, dort gibt es dann auch keine Probleme. Über den Browser hat eine PHP-Datei nur eine beschränkte Ausführungszeit, dann wird der Import abgebrochen und ihr seht eine Fehlermeldung eures Browsers („Zeitüberschreitung“).
Keine Sorge, dies ist nicht weiter problematisch und der Entwickler des Skripts hat dies berücksichtigt. Ladet einfach die Seite neu, nachdem der Fehler aufgetreten ist. Dies wiederholt ihr nach jeder Fehlermeldung. Je nach Server, auf dem ihr euren Webspace habt, kann mit einem Mal laden zwischen 2500 und 5000 Tweets importiert werden. So könnt ihr grob überschlagen, wie oft ihr die Seite aufrufen müsst.
Versucht aber nicht wie im Wahn die Seite neu zu laden, dass beschleunigt nichts. Also immer erst die Fehlermeldung abwarten und schauen, dass der Browser nicht noch versucht die Seite zu laden. Bei den meisten Anbietern ist das Timeout auf 60 Sekunden gesetzt, d.h., nach 60 Sekunden wird der Import abgebrochen und erst dann ladet ihr die Seite neu.
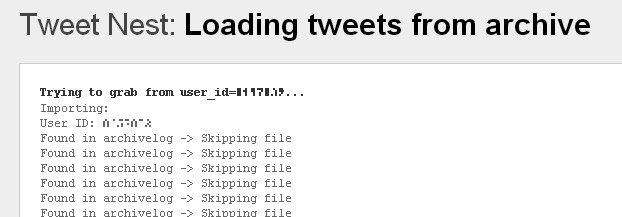
Wenn ihr dann die Seite „Tweet Nest: Loading tweets from archive“ seht, dann ist der Import komplett abgeschlossen.
Nun könnt ihr Tweetnest benutzen.
 Damit Tweetnest auch eure zukünftigen Tweets empfangen kann, müsst ihr regelmäßig die Seite „maintenance/loadtweets.php“ aufrufen. Bei diesem Aufruf werden maximal 3200 Tweets der Vergangenheit geladen, wer also extrem häufig twittert, muss die Aktualisierung häufiger laufen lassen als der wenig-Twitterer.
Damit Tweetnest auch eure zukünftigen Tweets empfangen kann, müsst ihr regelmäßig die Seite „maintenance/loadtweets.php“ aufrufen. Bei diesem Aufruf werden maximal 3200 Tweets der Vergangenheit geladen, wer also extrem häufig twittert, muss die Aktualisierung häufiger laufen lassen als der wenig-Twitterer.



















Die Kommentare